Training Settings#
To open the Training Settings press  Settings in the Training Window.
Settings in the Training Window.
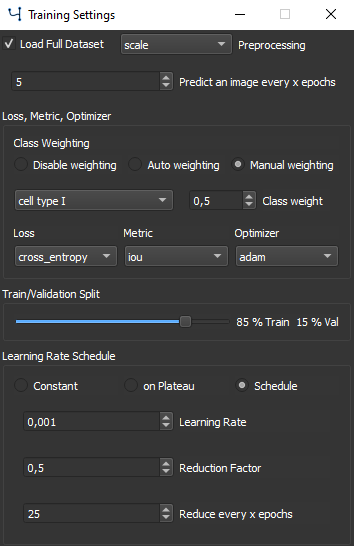
The Training Setting Window#
Check Load Full Dataset to completely load the data in the memory. When only limited memory is available uncheck and the images are loaded dynamically during training which might decrease training speed.
Choose a Preprocessing option to be performed with each image before training.
Predict an image every x epochs can be selected to make a prediction after the given epochs of the currently selected image. This option only applies if the Test Folder with a target image is selected.
Class Weights#
Class Weighting can be chosen from 3 different options:
Disable Weighting: No class weighting is applied.
Auto Weighting: Class weighting is calculated automatically based on the training data.
Manual Weighting: Select a weighting for each class individually by using the drop down menu and the corresponding edit field.
Tip
Class imbalance is a commonly occurring challenge for any machine learning task, as non-artifical data sets are usually not balanced. When using manual weighting, underrepresented class labels should get a higher weighting. In MIA different class balancing options exist: class weighting, specialized loss functions and suppression of background patches.
Loss, Metrics, Optimizer#
For losses and metrics please refer to Applications, as losses and metrics differ depending on application.
For optimizer different options exist:
Adam - Adaptive momentum optimizer [1]
AdaMax - variant of Adam based on infinity norm [1]
Adadelta - adaptive learning rate per dimension [2]
AdaGrad - parameter specific learning rates [3]
SGD - stochastic gradient decent with momentum [4]
Tip
Adam optimizer is widely used for deep learning projects because of its capability of fast convergence. However less adaptive methods, like sgd, are for some tasks considered to generalize better [5]. Use Adam as a starting point, but consider to use plain sgd when having a well curated, big data set.
Train / Validation Split#
It is common practice to split your training data in a training and validation set. The validation set is excluded from training and used to measure the model performance. Use the slider to set the train/validation split. The validation data is evaluated once every epoch. The larger the training set, the lower percentage needed for validation.
Note
The train / validation split is chosen randomly from training images, so when starting a training a new validation set is created. By resuming training the split is kept.
Learning Rate Schedule#
For Learning Rate adaptation 3 options exist:
Constant: Use a constant learning rate throughout training.
on Plateau: The learning rate is reduced by the set factor if the loss remains constant for the set number of epochs.
Schedule: Set a learning rate schedule that reduces the learning rate by the reduction factor after every set epochs.